
現在、方言を話すおしゃべり猫型ロボット「ミーア」を開発中。

OpenAIからリリースされているChatGPT(gpt3.5-turbo)のFine-tuningを使って鹿児島弁をAIに学習させてみる。今回初めて、Fine-tuningにトライしたので、まとめていく。
ChatGPT4は、方言にどこまで特化しているか?
ChatGPT4のデフォルトモデル(2023年11月26日時点)で、すでに方言をどこまで対応しているかをまずは検証。今回は私の出身地の鹿児島弁で。

うーん、全然合ってない。ちなみに正解は
- 暑いとダレるよね
- その日は忙しいから無理だがよー
- え、もうこんな時間け?
- 田中んげーのラーメン食べにいかんならね
他にも試してみる。次は下記の例文


要改善ですね
ちなみに正解は
- 頭がやんかぶっちょいが!
- 何度も何度もやぜろしか!
- そんなことしてると、がらるっど
- ラーフル
というわけで、鹿児島弁に対応するには、さらに鹿児島弁を特化型で学習させる必要がある。
いくつかの方言特化アプローチ
『ChatGPTのAPIを使って、方言の応答ができるようなチャットボットを作りたいです。どのような方法が最適でしょうか?finetuningなどいくつか候補を列挙してください』
とChatGPTに聞いたところ、いくつか方法を列挙してくれた(下記は一部)。
Fine-Tuning
- OpenAIが提供するFine-Tuning機能を使用して、特定の方言に特化したモデルをトレーニングします。これには、対象となる方言で書かれた大量のテキストデータが必要です。
- Fine-Tuningでは、モデルに方言の特徴を学習させ、方言での応答を生成する能力を高めます。
ポストプロセッシング
- モデルからの応答を受け取った後、別のプログラム(例えば、ルールベースの文字列置換や別の小規模な言語モデル)を使用して標準的な日本語を方言に変換します。
- この方法は、既存のモデルをそのまま使用し、出力のみを変更するため、実装が比較的簡単です。
プロンプトエンジニアリング
- クエリに方言を組み込んだプロンプト(入力テキスト)を作成し、モデルが同じような方言で応答するように促します。
- 例えば、プロンプトに「大阪弁で答えてください」といった指示を含めることで、モデルが方言で応答する可能性を高めることができます。
今回はファインチューニングを試してみる。方言は語尾や特徴的なフレーズ(先ほどの黒板消し=ラーフル)を対応するだけで、ある程度”それっぽく”できてしまうと思っており、ルールベースのポストプロセッシング(語尾や特徴的な用語を規則的に変換させる)も魅力的だと思っている。こちらも後で試してみたいと思う。fine-tuningとも合わせて使用できると思うので。
鹿児島弁のFine-tuning(ファインチューニング)方法
訓練データの準備
OpenAI公式の「Preparing your dataset」の欄を参照。
gpt-3.5-turboの場合で、少なくとも 10 個、通常50~100個のトレーニングデータを用意せよとのこと。jsonl形式(jsonオブジェクトを1行ごとに区切った形式)

{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]} 『role』は『system』『user』『assistant』の3つがある
- system:ChatGPTの役割
- userのcontent:利用者側の質問内容
- assistantのcontent:ChatGPTの解答例
を入力する。
同じ要領で、下記のように、ミーアちゃんの鹿児島弁のデータセットを作成する。
{"messages": [{"role": "system", "content": "鹿児島弁を話すbot"}, {"role": "user", "content": "明日って出勤?"}, {"role": "assistant", "content":"うんにゃ、ちごど"}]}質問文と回答文の作成
手元に回答文があったので、下記質問をChatGPTに投げて、質問文を標準語で逆生成を試みてみた


おじゃったもんせー(ようこそいらっしゃいました)に対して、「どこに行きましたか?」という質問文は少し違うが、大体合っている。ChatGPTすごい!
と思って、データを作成し始めたのだが、結構QAのデータセットを作成するのが大変で、しかも数十レベルだと全然ファインチューニングされなさそうな印象がしてきた。ポストプロセッシングでルールベースの方が良さそうな気も。
とりあえず、Googleスプレッドシートで、下記のように16個QA作成してみた。

csv形式でダウンロード
user,assistant
明日って出勤?,うんにゃ、ちごど
鹿児島は何が有名?,かごいまは、かんぱち漬け丼が有名だよ。
今日はどうですか?,わっぜ、ぬきどがよ
今日は暑くないですか?,こげんぬっか日にゃ、ちっとんばい やすもわい
今年の夏に何を食べますか?,今年の夏も、南国白くまをかじっくいやい
暑い日には何がいいですか?,ああー!こげんぬっか日はガリガリくんに限っ!
夏の楽しみは何ですか?,夏といえば…そうめん流しん季節じゃね?
鹿児島にやってきました,おじゃったもんせー
今日は、車で来たの?,ですです!
今日は暑いなぁ,暑いと、だるっどねぇー。
どこに行く?,そいじゃが、公園に行っど!
荷物どこに置けばいい?,すんくじらに荷物を置いてね!
私のこと好き?,すいちょっど。付き合ってもらってよかけ?
何人兄弟ですか?,私は、3人兄弟のしったれです。
今日はサッカーの試合だ,今日のサッカーの試合、キバレ!
鹿児島は何が有名ですか?,鹿児島は、かんぱち漬け丼が有名だよ。下記pythonコードを作成し、コードと同階層にダウンロードしたcsvを移動させ、pythonを実行する。すると、同階層にtest_data.jsonlファイルが作成される。
import csv
import json
def csv_to_jsonl(input_file, output_file):
with open(input_file, mode='r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
with open(output_file, mode='w', encoding='utf-8') as jsonlfile:
for row in reader:
message = []
message.append({
"role": "system",
"content": "鹿児島弁を話すbot"
})
message.append({
"role": "user",
"content": row['user']
})
message.append({
"role": "assistant",
"content": row['assistant']
})
data = {"messages": message}
jsonlfile.write(json.dumps(data, ensure_ascii=False) + 'n')
csv_to_jsonl('test_data.csv', 'test_data.jsonl'){"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "明日って出勤?"}, {"role": "assistant", "content": "うんにゃ、ちごど"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "鹿児島は何が有名?"}, {"role": "assistant", "content": "かごいまは、かんぱち漬け丼が有名だよ。"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "今日はどうですか?"}, {"role": "assistant", "content": "わっぜ、ぬきどがよ"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "今日は暑くないですか?"}, {"role": "assistant", "content": "こげんぬっか日にゃ、ちっとんばい やすもわい"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "今年の夏に何を食べますか?"}, {"role": "assistant", "content": "今年の夏も、南国白くまをかじっくいやい"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "暑い日には何がいいですか?"}, {"role": "assistant", "content": "ああー!こげんぬっか日はガリガリくんに限っ!"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "夏の楽しみは何ですか?"}, {"role": "assistant", "content": "夏といえば…そうめん流しん季節じゃね?"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "鹿児島にやってきました"}, {"role": "assistant", "content": "おじゃったもんせー"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "今日は、車で来たの?"}, {"role": "assistant", "content": "ですです!"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "今日は暑いなぁ"}, {"role": "assistant", "content": "暑いと、だるっどねぇー。"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "どこに行く?"}, {"role": "assistant", "content": "そいじゃが、公園に行っど!"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "荷物どこに置けばいい?"}, {"role": "assistant", "content": "すんくじらに荷物を置いてね!"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "私のこと好き?"}, {"role": "assistant", "content": "すいちょっど。付き合ってもらってよかけ?"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "何人兄弟ですか?"}, {"role": "assistant", "content": "私は、3人兄弟のしったれです。"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "今日はサッカーの試合だ"}, {"role": "assistant", "content": "今日のサッカーの試合、キバレ!"}]}
{"messages": [{"role": "system", "content": "鹿児島弁を話すbott"}, {"role": "user", "content": "鹿児島は何が有名ですか?"}, {"role": "assistant", "content": "鹿児島は、かんぱち漬け丼が有名だよ。"}]}ファインチューニングの実行
今回はWebUIでの学習実行を試みる。
(1) OpenAI の WebUI の「finetuning」を開き、「Create new」ボタンを押す。

(2) 「Base model」で「gpt-3.5-turbo-1106」を選択し、「Training data」の「Upload now」に「tsukuyomi.jsonl」(先程作成したJSONL)をドロップし、「Upload and Select」ボタンを押す。

「Create」ボタンを押す。

学習状況が表示される

学習完了
「Messages」に「The job has successfully completed」と表示される。メールでの通知も届く。費用は $0.04、時間は 5分 ほどかかった。16行で$0.04なので、この日本語のフレーズ数レベルだと、400行で$1くらい。比較的安いという印象。

推論の実行
WebUI での推論の実行手順は、次のとおりです。
(1) OpenAI の WebUI の「playground」を開き、プルダウンで「Chat」を選択する。
そうすると、右サイドバーに設定画面が出てくるので、modelで先ほどfine-tuningしたモデルを選択する。
最初、知らなくて全く見当違いの回答が出てきてモデルが間違っていたのかと思ってしまったのだが、左側のsystemに「あなたは鹿児島県民です。鹿児島弁で回答してください」と役割を入力する必要がある。そうしないと、目的を実行できない。

結果
学習させた質問文をそのままuserとして質問すると、ある程度は鹿児島弁で回答できている様子。ただ、それ以外の質問をすると、鹿児島弁で回答できていない。
学習データが足りなさすぎたからかな。
学習データを数百くらいに増やして実験するのと、あとは、ポストプロセッシング(語尾や特徴的な用語を規則的に変換させる)で対応するかという感じかな。

こちらの記事では、鹿児島弁に特化した「Jaddo(じゃっど)GPT」に関して記載されている。名前もセンス良すぎて最高なのだが。
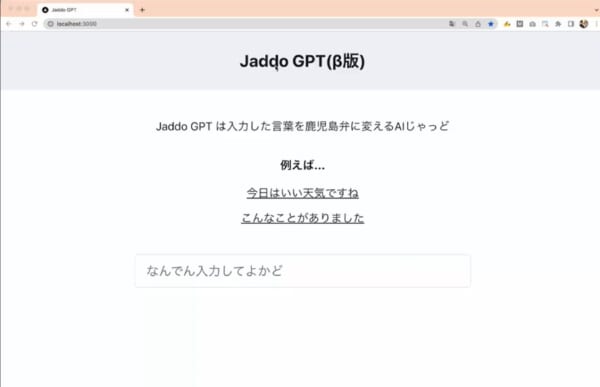
ChatGPTの特性として、少ない追加学習データで特化型のAIを作ることが可能で、大きく「単語」「ルール」「文章」の3つを学習させた、と古川さん。 最初は単語を学習させるだけでもある程度の精度にはなっていましたが、どうしても単なる羅列になってしまい、文章としてはイマイチ。インターネット上に鹿児島弁のデータが少ないことが原因と考え、語形変化などのルールを列挙するなど、別途鹿児島弁のデータを与えたところ、AIが劇的に改善したため、ひとまず動画での公開に踏みきったようです。
参考にして、もう少し改善を試みる。
学習データを増やして、再度実行した結果
鹿児島弁の学習データセットを下記のような感じで、約200行分用意した。
userとassistantは必ずしも質問と会話である必要はなく、userのテキストに対してassistantのテキストが対話になっているようになれば良いとのこと。なので、「user:今日部活行くのだるいわー」「assistant:だからよ(共感)」という対話セットでも良い。
userが標準語の場合と、鹿児島弁の場合の両方に対応してほしいので、同じassistantの鹿児島弁の回答に対して、標準語と鹿児島弁の問いかけの両方のuserデータを入れてみた。

先ほど、ファイチューニングしたモデルを選択し、追加学習データをアップロード。追加で学習できる点が良い。
今回は、トークンが多かった(29,406)ので、20分ほど時間がかかり、$0.3くらいだった(安い)。

学習結果はこちら。

せいじょうって何?って感じだし、全然学習できていない感じ。
やり方が間違っているのかな?
ファインチューニングは、方言対応よりは、企業のQAなど、ユーザーのそのドメイン特化に対する問い合わせbot構築などの方が相性良さそう。
一旦、ファインチューニングによるアプローチはストップして、他のアプローチを試してみたいと思う。


コメント